Sequential Query Expansion using Concept Graph
paper: “Sequential Query Expansion using Concept Graph” (pdf)
Objectives:
- To discover effective latent concepts for query expansion from manually and automatically constructed concept graphs (or semantic networks), in which the nodes correspond to words or phrases and the typed edges designate semantic relationships between words and phrases.
- To leverage large and dense concept graphs, in which the number of candidate concepts that are related to query terms and phrases and need to be examined increases exponentially with the distance from the original query concepts.
Example: Concept Graph from ConceptNet5 for the Query “poach wildlife preserve”:
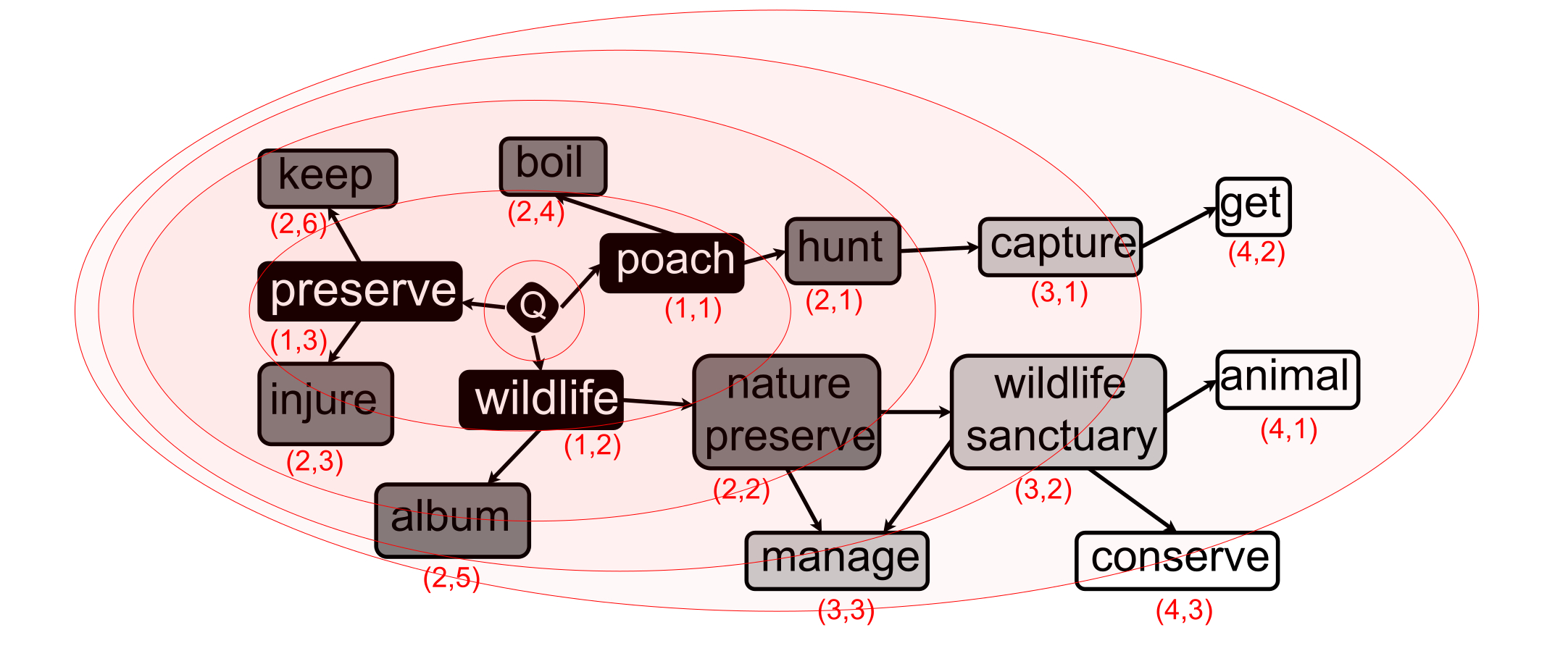
- Total number of concept layers that should involved in the concept selection process: 4
- Relationship layer 1:
- Number of examined concepts: 3
- Concepts should be Examined (all original concept in the query): “poach”, “wildlife”, “preserve”
- Concepts should be Selected: “poach”, “wildlife”, and “preserve”
- For simplicity, only unigram concepts are shown for the first layer in this figure.
- Relationship layer 2:
- Number of examined concepts: 6
- Concepts should be Examined (all concept directly related to original concepts): “keep”, “boil”, “hunt”, “nature preserve”, “album”, and “injure”
- Concepts should be Selected: “hunt” and “nature preserve”
- Relationship layer 3:
- Number of examined concepts: 3
- Concepts should be Examined (all concept directly related to selected concepts at layer 1): “capture”, “wildlife sanctuary”, and “manage”
- Concepts should be Selected: “capture” and “wildlife sanctuary”
- Relationship layer 4:
- Number of examined concepts: 3
- Concepts should be Examined (all concept directly related to selected concepts at layer 2): “get”, “animal”, and “conserve”
- Concepts should be Selected: None
Optimization Problem:
-
Objective: minimize number of examined concepts (and ultimately reduce the computation time)
-
Constraint: precision of retrieval results
Mathematical Formulation:
- : number of concept layers that are involved in the concept selection process
- : number of examined concepts at relationship layer
- : set of document rankings
- : set of training data
- retrieval quality evaluation metric for a set of document rankings, , based on the training data
- : a pre-specified lower threshold
- : set of all candidate concepts for selection (including original concepts)
Approximate Solution (Sequential Concept Selection):
STEP I: concepts are sorted using computationally “inexpensive” features:
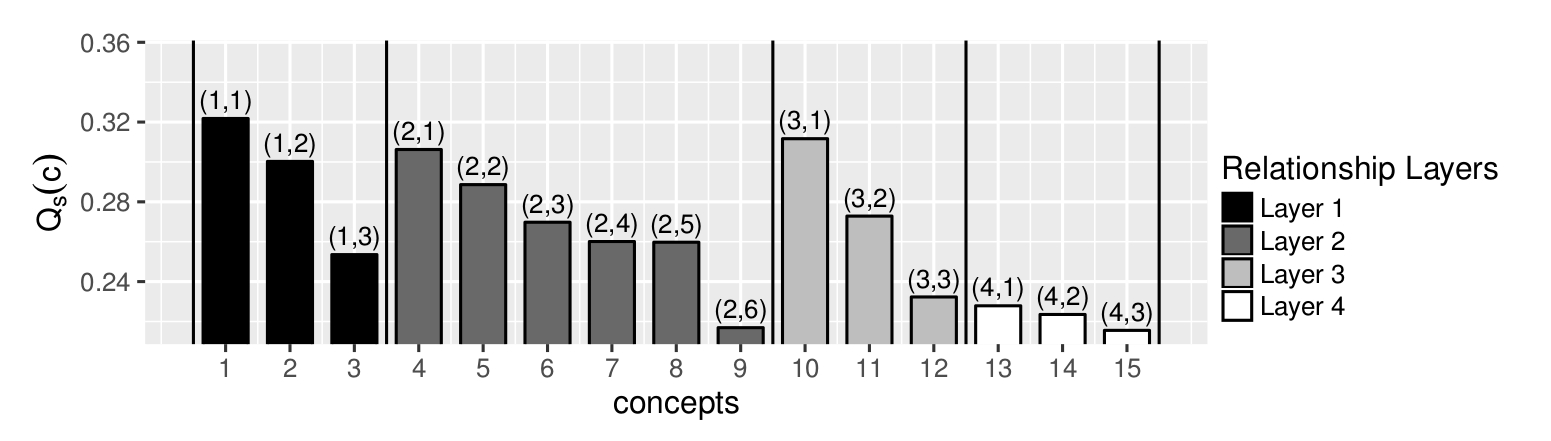
STEP II: This sorting is utilized in the second stage to sequentially select expansion concepts by using computationally “expensive” features:
| Criterion | Decision |
|---|---|
| If | Select concept and Continue with the same concept layer |
| If | Discard concept and Continue with the same concept layer |
| If | Discard concept and Move to the next concept layer |
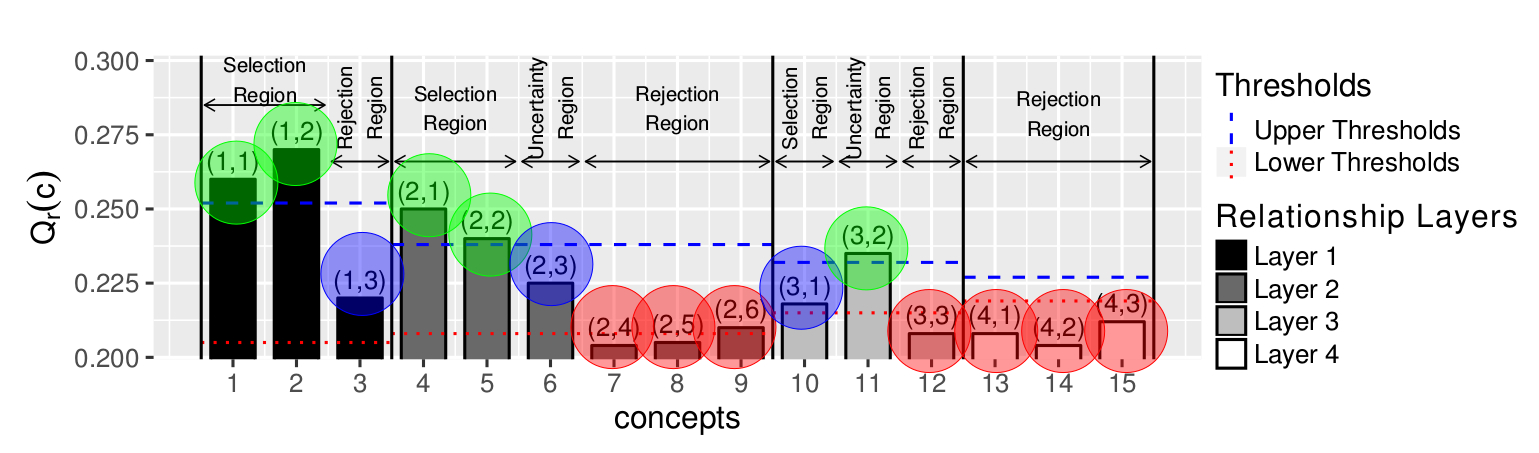
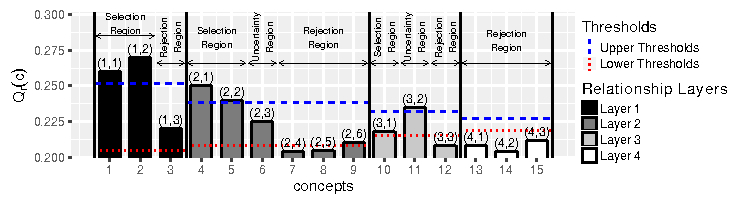
Parameter Optimization:
- Cross validation process: the following parameters are estimated:
- upper and lower threshold and for each concept relationship layer and at the stage II (shown by blue and red lines in the following figure).
- the weights of the features in stages I and II
- Retrieval evaluation metric: Mean Average Precision (MAP) of the top retrieved documents
- The goal in training is to keep MAP the threshold $\theta_Q$ (say 0.3), while the number of concepts examined in stage II is minimized.
- Coordinate ascent method: Starting from an initial random point, the parameter space is examined in uniform steps (e.g., step size was $0.01$), one parameter at a time. This process is repeated for all parameters until convergence (if the change in the target retrieval metric from one iteration to another is less than $0.05$) or until the number of iterations exceeds $100$.
- The values of threshold $\theta_Q$: should be chosen depending on the collection and based on the MAP value that is usually obtained by the baseline methods for that collection. Too large values for the threshold $\theta_Q$ may not result in an acceptable performance. For example, the values of $\theta_Q$ for TREC 7-8, ROBUST04 and GOV collections can be set to $0.28$, $0.32$, and $0.30$, respectively, all of which are greater than the MAP of the Query Likelihood method by $0.08$.
Features:
For ConceptNet5, features used in the stages I and II are shown in the following table. All of the listed features are considered in the second stage, but only the features without sign (inexpensive features) are considered in the first stage.
| Feature | Description |
|---|---|
| hgstDocScore | Retrieval score of the highest ranked document containing |
| avgDocScore | Average retrieval score of all documents containing |
| varDocScore | Variance of retrieval score of all documents containing |
| avgTDocScore | Average retrieval scores of the top documents containing |
| termFreqTpDoc | Number of occurrences of in the top documents |
| docFreqTpDoc | Number of top documents containing |
| nodeDegree | Node degree of in the concept graph |
| avgNumLinks | Average number of paths between and query concepts |
| maxNumLinks | Maximum number of paths between and query concepts |
| avgCooccur | Average co-occurrence of with query concepts |
| maxCooccur | Maximum co-occurrence of with query concepts |
| avgTCooccur | Average co-occurrence of with query concepts in top retrieved documents |
| maxTCooccur | Maximum co-occurrence of with query concepts in top retrieved documents |
| avgTCooccurP | Average co-occurrence of with at least a pair of query concepts in top retrieved documents |
| maxTCooccurP | Maximum co-occurrence of with at least a pair of query concepts in top retrieved documents |
| avgTCooccur | Average co-occurrence of with all previously selected concepts in top retrieved documents |
| maxTCooccur | Maximum co-occurrence of with all previously selected concepts in top retrieved documents |
| avgCooccurL | Average co-occurrence of with selected concepts in concept layer |
| maxCooccurL | Maximum co-occurrence of with selected concepts in concept layer |
| avgTCooccurL | Average co-occurrence of with selected concepts in concept layer in top retrieved documents |
| maxTCooccurL | Maximum co-occurrence of with selected concepts in concept layer in top retrieved documents |
| avgTMiP | Average mutual information of with at least a pair of query concepts in top retrieved documents |
| maxTMiP | Maximum mutual information of with at least a pair of query concepts in top retrieved documents |
| avgTMiL | Average mutual information of with selected concepts in concept layer in top retrieved documents |
| maxTMiL | Maximum mutual information of with selected concepts in concept layer in top retrieved documents |